단 24GB VRAM으로 DeepSeek 671B 모델을 구동하는 기술: KTransformers 설치 및 최적화 완벽 가이드
로컬 LLM의 새로운 시대, AirLLM을 넘어 KTransformers로
최근 1~2년 사이 인공지능 기술의 발전 속도는 그야말로 눈이 멀 정도입니다. 특히 2026년 현재, 우리는 더 이상 거대 언어 모델(LLM)을 활용하기 위해 거대 기업의 API에만 의존할 필요가 없는 시대를 살고 있습니다. 불과 얼마 전까지만 해도 AirLLM과 같은 기술을 통해 레이어를 쪼개어 VRAM의 한계를 극복하는 방식이 주목받았습니다. 하지만 AirLLM은 데이터를 메모리에 올리고 내리는 과정에서 발생하는 I/O 병목 현상으로 인해 추론 속도가 현저히 느리다는 치명적인 약점이 있었습니다.
이러한 한계를 정면으로 돌파하며 등장한 것이 바로 KTransformers입니다. 이 프레임워크는 최근 오픈 소스 생태계를 뒤흔든 DeepSeek-V3나 R1과 같은 MoE(Mixture of Experts, 전문가 믹스) 아키텍처 모델에 최적화되어 있습니다. 수천억 개의 파라미터를 가진 거대 모델을 일반 가정용 워크스테이션, 특히 단 24GB의 VRAM을 가진 RTX 3090이나 4090 한 장으로도 쾌적하게 돌릴 수 있게 해주는 혁신적인 기술입니다.
Blogger's Insight
IT 업계에서 20년 넘게 몸담으며 수많은 기술적 변곡점을 목격해 왔지만, 지금의 KTransformers가 보여주는 혁신은 과거 메인프레임에서 클라이언트-서버 모델로 전환되던 시기만큼이나 짜릿합니다. 예전에는 수억 원대 장비가 있어야 가능했던 연산이 이제는 내 책상 위 PC에서 가능해졌다는 사실이 놀랍습니다.
특히 제가 주목하는 점은 '효율성'입니다. 무조건 비싼 GPU를 여러 장 꽂는 것이 정답이 아니라, 이미 가지고 있는 CPU와 시스템 RAM을 어떻게 최적으로 활용할 것인가에 대한 해답을 KTransformers가 제시하고 있기 때문입니다. 이는 자본이 한정된 1인 창업자나 중소규모 개발사들에게 엄청난 기회의 창을 열어주는 것입니다. 기술의 민주화라는 것이 멀리 있는 게 아니라, 바로 이런 최적화 프레임워크 하나로 실현된다는 점이 이 일을 계속하게 만드는 원동력이 됩니다.
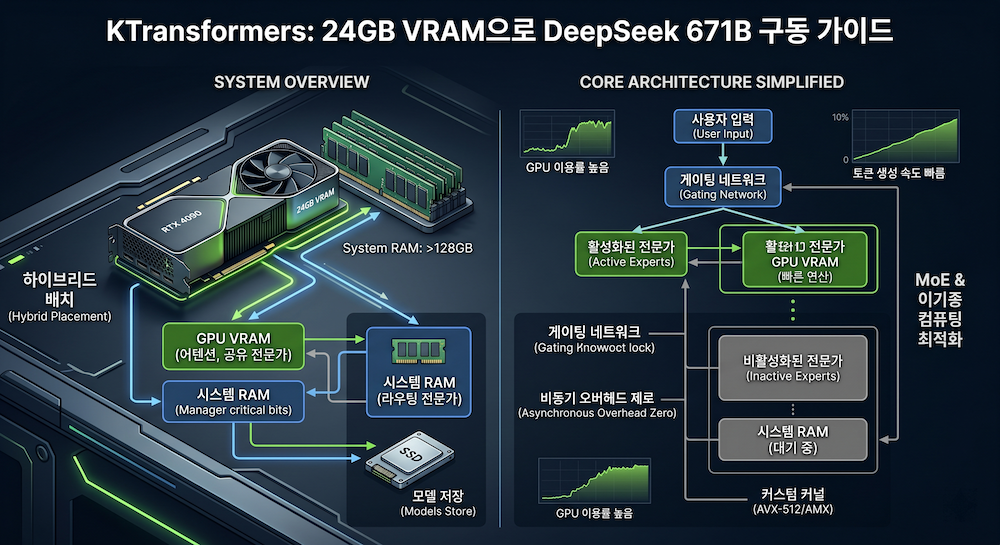
KTransformers 코어 아키텍처: CPU와 GPU의 완벽한 이중주
KTransformers의 핵심은 이기종 컴퓨팅(Heterogeneous Computing)에 있습니다. 기존의 방식들이 GPU의 VRAM 용량에 모든 것을 걸었다면, KTransformers는 영리하게 역할을 나눕니다.
1. 하이브리드 메모리 배치 전략
거대 MoE 모델의 모든 파라미터를 VRAM에 넣는 것은 물리적으로 불가능합니다. KTransformers는 연산이 가장 집중되는 Attention(어텐션) 계층과 모든 토큰 처리 시 공통으로 사용되는 Shared Expert(공유 전문가)는 속도가 빠른 GPU VRAM에 배치합니다. 반면, 전체 모델 크기의 대부분을 차지하지만 특정 질문에만 선택적으로 호출되는 **Routed Experts(라우팅 전문가)**는 상대적으로 용량이 넉넉하고 저렴한 시스템 RAM(DDR4/DDR5)에 상주 시킵니다.
2. 비동기 파이프라이닝과 통신 최적화
단순히 데이터를 나누어 담는 것에 그치지 않습니다. CPU에서 연산된 결과와 GPU의 결과가 만날 때 발생하는 병목을 줄이기 위해 고도의 비동기 처리 기술을 사용합니다. 이를 통해 GPU가 노는 시간 없이 지속적으로 토큰을 생성할 수 있는 구조를 완성했습니다.
Blogger's Insight
보험 시스템이나 대규모 금융 전산망을 운영할 때 가장 중요한 것이 '부하 분산'과 '자원 최적화'입니다. KTransformers의 아키텍처를 들여다보면 잘 짜인 금융 시스템의 트랜잭션 처리 구조를 보는 듯한 기분이 듭니다. 모든 데이터를 비싼 스토리지에 넣지 않고, 빈도에 따라 계층화(Tiering)하여 관리하는 방식과 매우 흡사하죠.
50대의 관점에서 볼 때, 이러한 기술은 단순히 '속도가 빠르다'는 것을 넘어 '지속 가능한 AI 환경'을 의미합니다. 하드웨어를 매번 최신형으로 교체하는 것은 비용 측면에서 매우 비효율적입니다. 하지만 소프트웨어적인 최적화로 기존 자원의 수명을 연장하고 성능을 극대화하는 이런 접근법이야말로 진짜 실력 있는 엔지니어링이라고 생각합니다. 우리는 흔히 최신 기술만 쫓아가기 바쁘지만, 본질은 결국 '한정된 자원을 어떻게 가장 영리하게 쓸 것인가'에 달려 있습니다.
내 PC에 수천억 파라미터 거인 깨우기: 설치 및 실전 추론
KTransformers를 실제로 구축하기 위해서는 몇 가지 준비물이 필요합니다. 2026년 현재 권장되는 사양은 24GB VRAM을 가진 GPU와 최소 128GB 이상의 시스템 RAM입니다.
환경 구축 및 커스텀 커널 설치
KTransformers는 일반적인 라이브러리 설치보다 조금 더 깊은 단계의 설정을 요구합니다.
Linux/WSL 기반 환경: 성능 손실을 최소화하기 위해 가급적 순수 리눅스 환경이나 최신 WSL2 환경을 권장합니다.
AVX-512 / AMX 최적화: 최신 인텔이나 AMD CPU가 제공하는 가속 명령어를 사용하기 위해 소스 코드를 직접 컴파일하여 커스텀 커널을 생성해야 합니다. 이 과정이 KTransformers의 속도를 결정짓는 핵심입니다.
DeepSeek 모델 로드와 테스트
Hugging Face에서 제공하는 DeepSeek-V3-GGUF 또는 Safetensors 형식을 활용하여 모델을 로드합니다. 파이썬 스크립트 하나로 수천억 파라미터의 모델이 내 터미널에서 대답을 내놓는 순간은 그야말로 전율이 느껴지는 경험입니다.
Blogger's Insight
직접 커널을 컴파일하고 환경을 세팅하는 과정이 요새 젊은 친구들에게는 조금 번거롭게 느껴질 수도 있을 겁니다. 클릭 한 번으로 끝나는 SaaS 서비스가 워낙 잘 되어 있으니까요. 하지만 저는 이 과정을 마치 정밀한 기계를 조립하거나, 귀한 차를 직접 우려내는 과정에 비유하고 싶습니다.
손수 환경을 구축하며 발생하는 에러를 해결하고, 내 시스템에 딱 맞는 최적화 값을 찾아가는 과정에서 비로소 이 기술이 온전히 내 것이 됩니다. 2026년의 AI는 단순히 '사용하는 도구'를 넘어 '함께 성장하는 파트너'에 가깝습니다. 내가 직접 공들여 세팅한 로컬 서버에서 딥시크(DeepSeek)가 유창하게 답을 하는 모습을 보면, 마치 잘 키운 자식이 대견한 성과를 내는 것과 같은 뿌듯함을 느낍니다. 이것이 바로 로컬 LLM 운영의 진정한 묘미이자 즐거움 아니겠습니까?
성능을 극한으로 끌어올리는 시스템 최적화 비법
단순히 실행되는 것에 만족하지 않는다면, 시스템의 깊은 곳을 건드려야 합니다.
NUMA 아키텍처와 스레드 바인딩
멀티 코어 CPU, 특히 듀얼 소켓 시스템이나 고성능 워크스테이션을 사용 중이라면 NUMA(Non-Uniform Memory Access) 설정을 반드시 체크해야 합니다. 특정 메모리 영역이 특정 CPU 코어와 더 가깝게 연결되어 있기 때문에, KTransformers 설정에서 스레드 바인딩을 적절히 해주면 토큰 생성 속도가 20~30% 이상 향상됩니다.
양자화(Quantization) 전략의 선택
시스템 RAM이 128GB라고 해도 DeepSeek 671B 모델을 풀 파라미터로 올리기는 벅찹니다. 이때 중요한 것이 Q4_K_M이나 IQ4_XS 같은 고효율 양자화 포맷입니다. 성능 저하는 최소화하면서 메모리 점유율을 획기적으로 낮추는 안목이 필요합니다.
Blogger's Insight
최적화라는 것은 결국 '타협의 미학'입니다. 모든 것을 최고로 가질 수 없다면, 내가 필요한 부분에서 최선의 선택을 하는 것이죠. 50대를 지나오며 삶에서 배운 교훈 중 하나는 '과유불급'입니다. 무조건 무거운 모델을 돌리려 하기보다, 내 시스템 사양에 맞춰 적절한 양자화 수준을 찾고 안정적인 속도를 확보하는 것이 실무적으로 훨씬 가치 있습니다.
특히 NUMA 설정이나 스레드 할당 같은 부분은 기본기가 탄탄한 엔지니어들만이 누릴 수 있는 영역입니다. 겉으로 화려해 보이는 AI 기술 뒤에는 이러한 묵직한 하드웨어 이해도가 뒷받침되어야 합니다. 저는 우리 블로그 독자들이 단순히 유행하는 모델을 돌려보는 것에 그치지 않고, 시스템의 밑바닥까지 이해하며 장비를 장악하는 희열을 느껴보셨으면 합니다. 그것이 바로 전문가와 비전문가를 가르는 결정적인 한 끗 차이가 될 테니까요.
KTransformers 실전 서버 구축과 미래 청사진
이제 로컬에서 구동되는 이 거대 모델을 나만의 API 서버로 만들어야 합니다. FastAPI를 활용해 OpenAI와 호환되는 REST API를 구축하면, 외부에서도 내 로컬 DeepSeek 모델에 접속할 수 있습니다.
Open WebUI나 AnythingLLM 같은 도구와 결합하면, 회사 내부에서 보안 걱정 없이 사용할 수 있는 완벽한 전용 ChatGPT 환경이 완성됩니다. 이는 데이터 유출에 민감한 기업들이 2026년 현재 가장 선호하는 아키텍처이기도 합니다.
Blogger's Insight
결국 우리가 기술을 공부하는 목적은 실생활이나 비즈니스에 적용하기 위함입니다. 로컬 LLM 서버를 구축하는 것은 나만의 지식 저장소를 만드는 것과 같습니다. 제가 거주하는 서울의 역동적인 비즈니스 환경에서도 이런 프라이빗 AI에 대한 갈증이 상당합니다.
앞으로의 미래는 단순히 똑똑한 AI를 쓰는 사람이 아니라, AI를 어디에 어떻게 배치할지 설계하는 '아키텍트'의 시대가 될 것입니다. KTransformers는 그 설계를 가능하게 하는 아주 강력한 도구입니다. 50대의 연륜으로 감히 조언하자면, 지금 이 기술을 익혀두는 것은 미래를 위한 가장 확실한 보험을 드는 것과 같습니다. 변화를 두려워하지 말고, 이 파도에 몸을 실어 보십시오. 제가 그 길을 계속해서 안내해 드리겠습니다.
핵심 태그
#KTransformers #DeepSeekV3 #로컬LLM #MoE아키텍처 #24GBVRAM #인공지능최적화 #이기종컴퓨팅 #AI서버구축 #DeepSeekR1 #LLM최적화가이드
You should also read:

Seasonal Mood: Spring
2026년 봄 서울 도심의 분주함을 잊게 할 사진 2026년의 봄은 유난히 따뜻한 햇살과 함께 우리 곁으로 찾아왔습니다. 기술이 비약적으로 발전하고 모든 것이 데이터로 환산되는 시대에 살고 있지만, 역설적으로 사람들은 더욱 따스한 인간미와 정서적 울림을 갈구하고 있습니다. 올해의 서울 색인 ‘모닝 옐로우(Morning Yellow)’가 도시 곳곳을 물들이는…
Continue reading...
지금까지 나와의 대화를 분석해서 솔직한 내 모습을 표현하는 프로필 포스터를 그려!
AI : 제미나이 프롬프트 : 지금까지 나와의 대화를 분석해서 솔직한 내 모습을 표현하는 프로필 포스터를 그려
Continue reading...
2026년 봄, 일상의 여유를 더하는 시티팝과 로파이 감성 플레이리스트: ROMI 채널의 매력적인 선곡 분석
2026년의 봄은 유난히 따뜻한 햇살과 함께 찾아왔습니다. 기술이 비약적으로 발전하고 일상의 속도가 더욱 빨라진 지금, 역설적으로 우리는 마음을 진정시켜 줄 '감성'과 '휴식'을 더욱 갈구하게 됩니다. 이러한 시대적 흐름 속에서 최근 유튜브 음악 채널 'ROMI'가 선보인 플레이리스트는 세련된 도시적 감각과 정서적 위로를 동시에 선사하며 많은 이들의…
Continue reading...